7. Ensembles [파이썬으로 배우는 데이터 사이언스]

Ensembles |
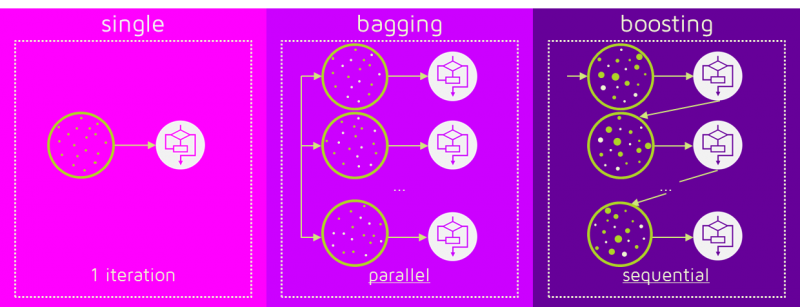
앙상블: 다양한 모델들을 합쳐 하나의 모델을 만드는 것.
Contents:
1. Bagging(Bootstrap Aggregating)
2. Boosting
3. Stacking
4. Voting
1. Bagging(Bootstrap Aggregating)
- 모델을 일반화 한다. (high variance -> low variance)
- 서로 다른 트레이닝 데이터의 subsamples로 많은 수의 모델들을 만드는 것.
- 이러한 subsamples 로부터 분산을 줄여 모델의 Variance를 줄인다.
- random sampling. (데이터를 샘플링 할 때, 중복을 허용한다)
- 병렬적으로 random sampling된 데이터들을 학습 한다.
- overfitting(low bias, high variance) 모델들에 대하여 적합하다.
- 모델들을 합칠 때, 카테고리 데이터인 경우 "Voting" / 연속적인 데이터인 경우 "Average".
#Bagged Decision Trees
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
kfold=KFold(n_splits=10, random_state=6)
cart=DecisionTreeClassifier()
model=BagginingClassifier(base_estimator=cart, n_estimators=100, random_state=6)
results=cross_val_score(model, X, y, cv=kfold)
print(results.mean())
- Random Forest
· 각각의 classifiers 사이에 correlation을 줄이며 트리를 만든다.
· split 과정에서 랜덤한 features subset이 고려된다. (not a greedily choose for best split)
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
kfold=KFold(n_splits=10, random_state=6)
model=RandomForestClassifier(n_estimators=100, max_features=3)
results=cross_val_score(model, X, y, cv=kfold)
print(results.mean())
- Extra Trees
· 트레이닝 데이터셋의 샘플 들로부터 랜덤 트리들이 만들어진다.
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
kfold=KFold(n_splits=10, random_state=6)
model=ExtraTreesClassifier(n_estimators=100, max_features=3)
results=cross_val_score(model, X, y, cv=kfold)
print(results.mean())
2. Boosting
- 어려운 문제를 푸는데 좋다. (정확도가 높게 나오지만 새로운 데이터에 취약하다)
- 순차적으로 weak leaners을 학습하여 모델을 만든다. 각각의 weak learner들에 대하여 그 이전의 잘못 예측한 데이터들에 대하여 가중치를 주어 학습한다. 그 이후 최종 모델이 만들어지면 결과에 따라서 가중치를 재분배 한다.
ex)
· 먼저 weak leaner 1번 으로 전체 데이터를 학습시킨다.
· 1번에서 에러가 큰 데이터에 대하여 weak learner 2 번으로 학습시킨다.
· 이렇게 쭉 반복하여 순차적으로 weak learner들을 학습시킨다.
- 순차적인 특성에 의해 bagging에 비해 속도가 많이 느리다.
- 가중치를 선형 결합하고 데이터가 많을 때 좋다.
#AdaBoost
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import AdaBoostClassifier
kfold=KFold(n_splits=10, random_state=6)
model=AdaBoostClassifier(n_estimators=100, random_state=6)
results=cross_val_score(model, X, y, cv=kfold)
print(results.mean())
#Stochastic Gradient Boosting
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
kfold=KFold(n_splits=10, random_state=6)
model=GradientBoostingClassifier(n_estimators=100, random_state=6)
results=cross_val_score(model, X, y, cv=kfold)
print(results.mean())
#XGBoost
CART 개념도입, 각 tree와 lead에 CART를 넣고 lead 별로 점수를 주고 이를 이용해 학습.
3. Stacking
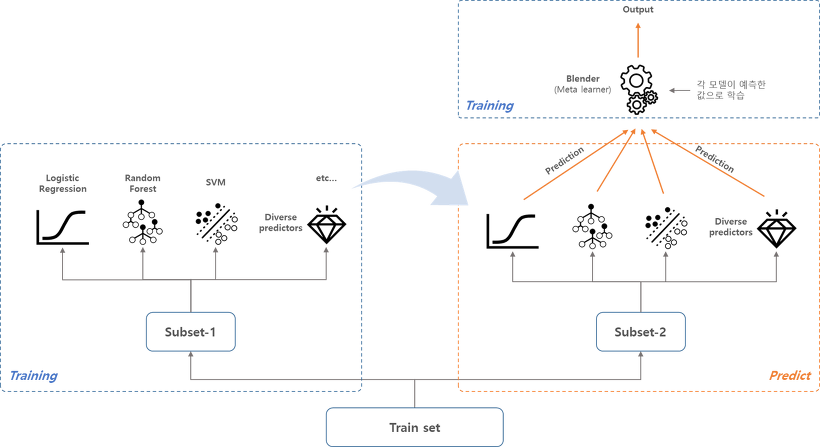
- 서로 다른 모델들을 합쳐서 새로운 모델을 만드는 것.(Bagging / Boosting은 동일 한 모델을 subsampling 을 통한 방법으로 합쳤었다.)
- 많은 computation이 필요하다.(오래 걸린다)
- StackNet: Stacking을 Neural Network 방식으로 여러 Layer로 구성한 방법이다.
스태킹(stacking)의 과정:
1) 트레이닝 데이터에서 샘플링을 통해 subset-1을 만들고, 이걸로 각 모델을 학습시킨다.
2) subset-2로 a에서 만들어진 모델들을 예측하고 각각의 예측 값을 합친다.
3) 위에서 만들어진 예측 값의 합을 input으로 하는 최종적인 모델(meta learner)을 학습시킨다.
3. Voting
- 서로 다른 알고리즘의 모델들을 간단한 통계학(평균)을 사용하여 예측 값을 합치는 것.
- 여러개 M.L 알고리즘 모델 학습 → 새로운 데이터에 모델 예측 값을 가지고
- 다수결 투표("hard voting")를 통해 최종 클래스 예측.
- 앙상블 기법에서 독립적인 모델을 만들어 주기 위해서 다른 M.C 알고리즘으로 학습시키는 것이 좋다. (모델별로 서로 다른 종류의 오차를 가짐으로 상관관계가 작아지기 때문)
· voting='hard'인 경우, 각 classifier의 "레이블"을 가지고 voting.
· voting='soft'인 경우, 각 classifier의 "확률"을 가지고 평균이 가장 높은 클래스를 최종 ensemble 예측.
from sklearn.model_selection import KFold, cross_val_score
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
kfold=KFold(n_splits=10, random_state=6)
estimators=[]
model1=LogisticClassifier(solver='liblinear')
model2=DecisionTreeClassifier()
model3=SVC(gamma='auto')
estimators.append( ('logistic',model1) )
estimators.append( ('cart',model2) )
estimators.append( ('svm',model3) )
ensemble=VotingClassifier(estimators)
results=cross_val_score(ensemble, X, y, cv=kfold)
print(results.mean())
data-learning.tistory.com
* 해당 게시물은 첫번째 배너 및 출처를 첨부하면 상업적 용도를 제외하고 사용하실수 있습니다.
'Machine Learning > 파이썬_데이터사이언스' 카테고리의 다른 글
| 9. Save / Load M.L Model [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.08 |
|---|---|
| 8. Parameter Tuning [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.08 |
| 6. Pipelines [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.05 |
| 5. Spot-Check Classification Algorithm [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.03 |
| 4. 머신러닝 모델 평가 [파이썬으로 배우는 데이터 사이언스] (0) | 2020.01.31 |
댓글