4. 머신러닝 모델 평가 [파이썬으로 배우는 데이터 사이언스]

Resampling을 통한 모델 퍼포먼스 평가 |
Contents:
1. train / test data로 나누기
2. K-fold Cross-validation
3. Leave One Out Cross-validation
4. 반복적인 랜덤 train / test data로 나누기
5. 적절한 테크닉을 언제 사용할지?
· 테스트 데이터에 대해 평가 하는 방법
· 기존 label 이 있는 데이터를 바탕으로 평가
· resampling을 통한 평가
· training data 바탕으로만한 평가 → overfitting
1. train/test data로 나누기
- train/test 비율 → 7:3 (or 6:4, 8:2 … 이러한 비율이 시작하기에 좋다) 하지만, high variance의 위험이 따른다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test=train_test_split(X,y,test_size=0.3,random_state=6)
model=LogisticRegression(solver='liblinear')
model.fit(X_train,y_train)
score=model.score(X_test,y_test)
print("Accuracy is %.3f%% "%(score*100))
2. K-fold Cross-validation
- 1번의 그냥 나눔보다 k-fold cross validation을 사용한다면, 더 작은 variance를 기대 할 수 있다.
- (k-1) 번 트레인 하고 나머지 한번을 테스트 한다. 이것을 k 번 반복한다.(서로 다른 테스트 데이터로 설정) 그리고 mean / std의 값으로 평가한다.
- 새로운 데이터를 평가 할 때, 이러한 평가 방법은 더욱 신뢰할 수 있다.
- 결과에 따라서 분포도를 예상할 수 있다.
from sklearn.model_selection import KFold,cross_val_score
from sklearn.linear_model import LogisticRegression
kfold=KFold(n_split=10, random_state=6)
model=LogisticRegression('liblinear')
accuracy=cross_val_score(model, X, y, cv=Kfold)
print("Accuracy is %.3f%% "%(accuracy.mean()*100))
print("std is %.3f "%(accuracy.std()))
3. Leave One Out Cross-validation
- k-fold 의 변형이다.
- k-fold cross validation에서 각각의 fold의 사이즈를 1로 하면 많은 측정 결과들을 준다. 이 결과는 더 많은 믿음직한 결과를 준다. 하지만 k fold에 비해서 많은 computation을 가지므로 결과를 얻는데 더 오래 걸린다.
from sklearn.model_selection import LeaveOneOut, cross_val_score
from sklearn.linear_model import LogisticRegression
loocv=LeaveOneOut()
model=LogisticRegression(solver='liblinear')
accuracy=cross_val_score(model,X,y,cv=loocv)
print("Accuracy is %.3f%% "%(accuracy.mean()*100))
print("std is %.3f "%(accuracy.std()))
4. 반복적인 랜덤 train / test data로 나누기
- 또다른 k-fold 의 변형이다.
- 반복적으로 나누고 평가하는 방법이다.
- 빠르게 구하고 variance 도 줄일 수 있지만, 중복되는 데이터를 반복적으로 학습 / 평가 할 수 있으므로 redundancy 문제를 야기 한다.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, ShuffleSplit
kfold=ShuffleSplit(n_split=10, test_size=0.3, random_state=6)
model=LogisticRegression(solver='liblinear')
accuracy=cross_val_score(model,X,y,cv=kfold)
print("Accuracy is %.3f%% "%(accuracy.mean()*100))
print("std is %.3f "%(accuracy.std()))
5. 적절한 테크닉을 언제 사용할지?
- k-fold 는 머신 러닝 알고리즘을 평가하는데 있어서 좋다.
- train/test split을 활용한 평가는 느린 알고리즘을 평가 하는데 빠르고, 많은 데이터 셋에 대하여 작은 bias를 가진다.
- Leave-One-Out과 같은 변형된 cross validation 방법들은 variance를 균형 있게 하고 괜찮은 퍼포먼스, 속도(for training), 데이터 셋을 준다.
- k를 뭐 로 할지 모르면 10으로 하는 것 을 추천한다.
Evaluation Metrics |
Contents:
1. 분류 평가 방법
2. 회귀 평가 방법
1. 분류 평가 방법
※Classification Accuracy
- tp+tn / tp+tn+fp+fn
- balanced data일때 평가 가능. (데이터가 unbalanced) (레이블 1이 990개, 레이블0이 10개와 같은 경우) Accuracy는 적합한 평가 방법이 아니다. (Over/Under sampling 해서 balance를 맞춰주지 않는 한)
from sklearn.model_selection import KFold,cross_val_score
from sklearn.linear_model import LinearRegression
kfold=KFold(n_splits=10,random_state=6)
model=LinearRegression(solver='liblinear')
accuracy=cross_val_score(model,X,y,cv=kfold,scoring='accuracy')
print("Accuracy is %.3f%% "%(accuracy.mean()*100))
print("std is %.3f "%(accuracy.std()))
※Logarithmic Loss
- 확률을 계산 할 때 쓰인다. ( 0 ~ 1 as confidence)
from sklearn.model_selection import KFold,cross_val_score
from sklearn.linear_model import LinearRegression
kfold=KFold(n_splits=10,random_state=6)
model=LinearRegression(solver='liblinear')
accuracy=cross_val_score(model,X,y,cv=kfold,scoring='neg_log_loss')
print("Accuracy is %.3f%% "%(accuracy.mean()*100))
print("std is %.3f "%(accuracy.std()))
- 작은 logloss가 좋다. (측정값이 ascending order로 자동 변환)
- Area Under ROC Curve
· binary classification 문제에 쓰인다.
· AUC: 모델의 positive/negative classes를 분류 하는 능력을 의미한다.
· area 가 1 이면 완벽한 클래스 분류를 의미한다.
· area 가 0.5 이면 50%, 즉 랜덤 분류를 의미한다. (의미 없다는 것)
· ROC 는 sensitivity / specificity으로 쪼갤 수 있다.
· binary classification는 sensitivity/specificity 의 trade-off 이다.
- Sensitivity (also called the true positive rate, the recall, or probability of detection in some fields) measures the proportion of actual positives that are correctly identified as such (e.g., the percentage of sick people who are correctly identified as having the condition).
- Specificity (also called the true negative rate) measures the proportion of actual negatives that are correctly identified as such (e.g., the percentage of healthy people who are correctly identified as not having the condition).



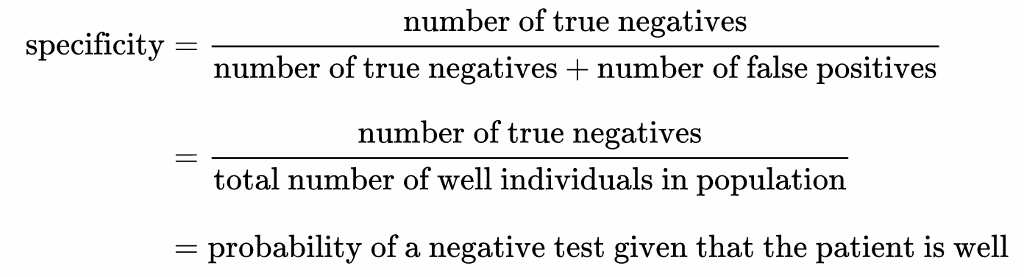
출처: <https://en.wikipedia.org/wiki/Sensitivity_and_specificity>
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score,KFold
kfold=ShuffleSplit(n_split=10, random_state=6)
model=LogisticRegression(solver='liblinear')
roc_auc=cross_val_score(model, X, y, cv=kfold, scoring='roc_auc')
print("Accuracy is %.3f "%(roc.mean()))
print("std is %.3f "%(roc.std()))
- Confusion Matrix
- from sklearn.metrics import classification_maxtrix
from sklearn.linear_model import LogisticRegression
from sklearn model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=6)
model=LogisticRegression(solver='liblinear')
model.fit(X.train,y_train)
prediction=model.predict(X_test)
matrix=confusion_matrix(Y_test,prediction)
print(matrix)
※Classification Report
- precision / recall /f1-score / support / (avg/total) 리포트 출력
- from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=6)
model=LogisticRegression(solver='liblinear')
model.fit(X.train,y_train)
prediction=model.predict(X_test)
report=classification_report(Y_test,prediction)
print(report)
2. 회귀 평가 방법
※Mean Absolute Error(MAE)
- sum(|Prediction- Actual_value|)
- 얼마나 예측한 게 잘못됐는지 알려준다.
- 크기는 주지만 방향성은 주지 않는다. (e.g. over/under predicting)
- from sklearn.linear_model import LinearRegression
from sklearn model_selection import KFold,cross_val_score
model=LinearRegression()
kfold=KFold(n_splits=10,random_state=6)
result=cross_val_score(model,X,y,cv=kfold,scoring='neg_mean_absolute_error')
print(result.mean(),result.std())
※Mean Squared Error(MSE)
- from sklearn.linear_model import LinearRegression
from sklearn model_selection import KFold,cross_val_score
model=LinearRegression()
kfold=KFold(n_splits=10,random_state=6)
result=cross_val_score(model,X,y,cv=kfold,scoring='neg_mean_squared_error')
print(result.mean(),result.std())
※R2(R Squared)
- coefficient of determination 이라고도 불린다.
- 0에서 1 사이의 값을 가지고, 0: no-fit, 1:perfect-fit 을 의미한다.
- from sklearn.linear_model import LinearRegression
from sklearn model_selection import KFold,cross_val_score
model=LinearRegression()
kfold=KFold(n_splits=10,random_state=6)
result=cross_val_score(model,X,y,cv=kfold,scoring='r2')
print(result.mean(),result.std())
data-learning.tistory.com
* 해당 게시물은 첫번째 배너 및 출처를 첨부하면 상업적 용도를 제외하고 사용하실수 있습니다.
'Machine Learning > 파이썬_데이터사이언스' 카테고리의 다른 글
| 6. Pipelines [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.05 |
|---|---|
| 5. Spot-Check Classification Algorithm [파이썬으로 배우는 데이터 사이언스] (0) | 2020.02.03 |
| 3. Feature Selection [파이썬으로 배우는 데이터 사이언스] (0) | 2020.01.30 |
| 2. 머신러닝을 위한 데이터 준비 [파이썬으로 배우는 데이터 사이언스] (0) | 2020.01.30 |
| 1. 기술통계학 바탕 데이터 이해 [파이썬으로 배우는 데이터 사이언스] (0) | 2020.01.30 |
댓글